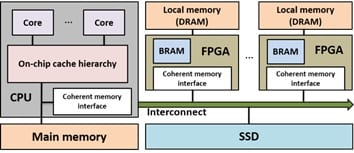
Management, search, query processing, and analysis of Big Data have become critical across the many stages of exploration, discovery, and refinement of innovations in computational science and engineering. While demand for computational resources continues to grow with increasing need for querying and analyzing the volumes and rates of Big Data, the semiconductor industry has reached its physical scaling limits. Due to this dark silicon challenge, hardware acceleration through specialization has received renewed interest. Heterogeneous architectures are particularly appealing for high-performance, low-cost Big Data management, processing and analysis for two reasons.
We devise algorithmic and architecture optimizations to leverage emerging heterogeneous platforms to accelerate the querying and analysis of large structured and graph datasets for Big Data applications. To facilitate the execution of data-intensive algorithms as a composition of tightly-coupled kernels, we also delve into techniques to exploit the unique features of compute components and their associated memory access capabilities.
AREAS OF INTEREST:
Graph Analytics, Accelerating Database Operations
PAGERANK IMPLEMENTATION ON FPGA
Recently, FPGA implementation of graph algorithms arising in many areas such as social networks has been studied. However, the irregular memory access pattern of graph algorithms makes it challenging to obtain high-performance. We develop an FPGA implementation of the classic PageRank algorithm. We optimize the overall system performance, especially the cost of accessing the off-chip DRAM. We optimize the data layout so that most of the memory accesses to the DRAM are sequential. Post-place-and-route results show that our design on a state-of-the-art FPGA can achieve a high clock rate of over 200 MHz. Based on a realistic DRAM access model, we build a simulator to estimate the execution time including memory access overheads. The simulation results show that our design achieves at least 96% of the theoretically best performance of the target platform. Compared with a baseline design, our optimized design dramatically reduces the number of random memory accesses and improves the execution time by at least 70%.
LARGE SCALE SORTING ON FPGA
Sorting is a key kernel in numerous big data application including database operations, graphs and text analytics. Due to low control overhead, parallel bitonic sorting networks are usually employed for hardware implementations to accelerate sorting. Although a typical implementation of merge sort network can lead to low latency and small memory usage, it suffers from low throughput due to the lack of parallelism in the final stage. We analyze a pipelined merge sort network, showing its theoretical limits in terms of latency, memory and, throughput. To increase the throughput, we propose a merge sort based hybrid design where the final few stages in the merge sort network are replaced with “folded” bitonic merge networks. In these “folded” networks, all the interconnection patterns are realized by streaming permutation networks (SPN). We present a theoretical analysis to quantify latency, memory, and throughput of our proposed design. Performance evaluations are performed by experiments on Xilinx Virtex-7 FPGA with post place-and-route results. We demonstrate that our implementation achieves a throughput close to 10 Gbps, outperforming state-of-the-art implementation of sorting on the same hardware by 1.2x while preserving lower latency and higher memory efficiency.
ACCELERATE DATABASE OPERATIONS ON HETEROGENEOUS PLATFORM
Accelerating database applications using FPGAs has recently been an area of growing interest in both academia and industry. Equi-join is one of the key database operations whose performance highly depends on the performance of sorting. However, as the data sets grow in scale, the database primitive sorting exhibits high memory usage on FPGA. A fully pipelined N-key merge sorter consists of log N sorting stages using O(N) memory totally. For sorting large data sets, external memory has to be employed to perform data buffering between the sorting stages after exhausting FPGA memory resource. This introduces pipeline stalls as well as several data communication iterations between FPGA and external memory, thus causing significant performance decline. To resolve this issue, we speed-up equi-join using a hybrid CPU-FPGA heterogeneous platform. To alleviate the burden of memory usage for sorting, we propose a merge sort based hybrid design where the first few sorting stages in the merge sort tree are replaced with “folded” bitonic sorting networks. These “folded” bitonic sorting networks work in parallel on the FPGA. The partial results are then merged on the CPU to produce the final sorted result. Based on this hybrid sorting design, we develop two streaming join algorithms, which are tailored to the target hybrid platform by optimizing the classic CPU-based nested-loop join and sort-merge join algorithms. On a range of data set sizes, our design achieves high throughput and performs 3.1x better than software-only and 1.9x better than accelerator only implementations. Our design sustains 21.6% of the peak bandwidth, which is 3.9x utilization obtained by the state-of-the-art FPGA equi-join implementation.
RECENT PUBLICATIONS
The following papers may have copyright restrictions. Downloads will have to adhere to these restrictions. They may not be reposted without explicit permission from the copyright holder.
-
- Wijeratne, Sasindu; Kannan, Rajgopal; Prasanna, Viktor, Reconfigurable Low-latency Memory System for Sparse Matricized Tensor Times Khatri-Rao Product on FPGA, IEEE High Performance Extreme Computing Conference, 2021
- Wijeratne, Sasindu; Pattnaik, Sanket; Chen, Zhiyu; Kannan, Rajgopal; Prasanna, Viktor, Programmable FPGA-based Memory Controller, IEEE Hot Interconnects symposium, 2021
- Yang, Yang; Kuppannagari, Sanmukh; Prasanna, Viktor K., A High Throughput Parallel Hash Table Accelerator on HBM-enabled FPGAs, IEEE ICFPT, 2020
- Zhang, Ruizhi; Wijeratne, Sasindu; Yang, Yang; Kuppannagari, Sanmukh; Prasanna, Viktor, A High Throughput Parallel Hash Table on FPGA using XOR-based Memory, IEEE HPEC, 2020