Graph Convolutiona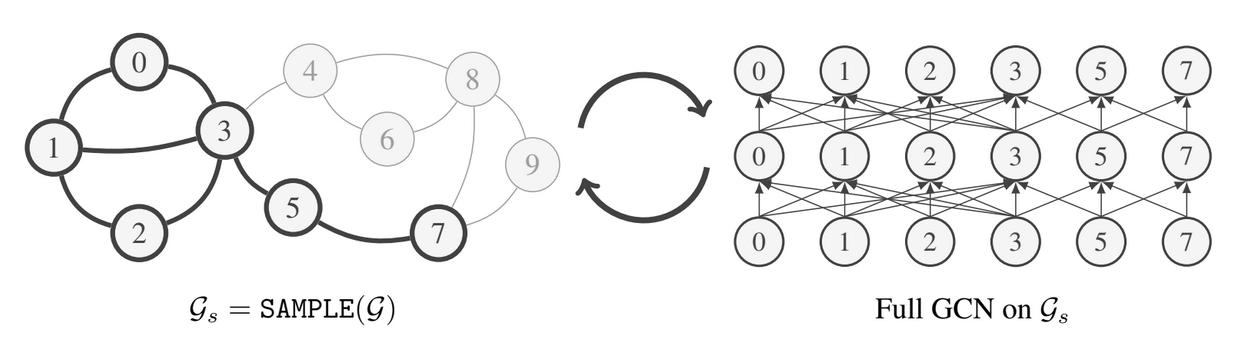 l Networks (GCNs) are powerful models for learning representations of attributed graphs. To scale GCNs to large graphs, state-of-the-art methods use various layer sampling techniques to alleviate the “neighbor explosion” problem during minibatch training. We propose GraphSAINT, a graph sampling based inductive learning method that improves training efficiency and accuracy in a fundamentally different way. By changing perspective, GraphSAINT constructs minibatches by sampling the training graph, rather than the nodes or edges across GCN layers. Each iteration, a complete GCN is built from the properly sampled subgraph. Thus, we ensure fixed number of well-connected nodes in all layers. We further propose normalization technique to eliminate bias, and sampling algorithms for variance reduction. Importantly, we can decouple the sampling from the forward and backward propagation, and extend GraphSAINT with many architecture variants (e.g., graph attention, jumping connection). GraphSAINT demonstrates superior performance in both accuracy and training time on five large graphs, and achieves new state-of-the-art F1 scores for PPI (0.995) and Reddit (0.970).
l Networks (GCNs) are powerful models for learning representations of attributed graphs. To scale GCNs to large graphs, state-of-the-art methods use various layer sampling techniques to alleviate the “neighbor explosion” problem during minibatch training. We propose GraphSAINT, a graph sampling based inductive learning method that improves training efficiency and accuracy in a fundamentally different way. By changing perspective, GraphSAINT constructs minibatches by sampling the training graph, rather than the nodes or edges across GCN layers. Each iteration, a complete GCN is built from the properly sampled subgraph. Thus, we ensure fixed number of well-connected nodes in all layers. We further propose normalization technique to eliminate bias, and sampling algorithms for variance reduction. Importantly, we can decouple the sampling from the forward and backward propagation, and extend GraphSAINT with many architecture variants (e.g., graph attention, jumping connection). GraphSAINT demonstrates superior performance in both accuracy and training time on five large graphs, and achieves new state-of-the-art F1 scores for PPI (0.995) and Reddit (0.970).
Most state-of-the-art models do not have significant accuracy gain beyond two to three layers. Deep GNNs fundamentally need to address: 1). expressivity challenge due to over smoothing, and 2). computation challenge due to neighborhood explosion. We propose a simple “deepGNN, shallow sampler” design principle to improve both the GNN accuracy and efficiency—to generate representation of a target node, we use a deep GNN to pass messages only within a shallow, localized subgraph. A properly sampled subgraph may exclude irrelevant or even noisy nodes, and still preserve the critical neighbor features and graph structures. The deep GNN then smooths the informative local signals to enhance feature learning, rather than oversmoothing the global graph signals into just “white noise”. We theoretically justify why the combination of deep GNNs with shallow samplers yields the best learning performance. We then propose various sampling algorithms and neural architecture extensions to achieve good empirical results. On the largest public graph dataset, ogbn-papers100M, we achieve state-of-the-art accuracy with an order of magnitude reduction in hardware cost.
AREAS OF INTEREST:
Graph Analytics, Cloud Computing, Memory Optimization, Acceleration on Heterogeneous Architectures, FPGA IP Core development
RECENT PUBLICATIONS:
Disclaimer: The following papers may have copyright restrictions. Downloads will have to adhere to these restrictions. They may not be reposted without explicit permission from the copyright holder. Any opinions, findings, and conclusions or recommendations expressed in these materials are those of the author(s) and do not necessarily reflect the views of the sponsors including National Science Foundation (NSF), Defense Advanced Research Projects Agency (DARPA), and any other sponsors listed in the publications.
- Zhou, Hongkuan, et al. “Accelerating Large Scale Real-Time GNN Inference using Channel Pruning“, VLDB 2021
- Zeng, Hanqing; Zhou, Hongkuan; Srivastava, Ajitesh; Kannan, Rajgopal; Prasanna, Viktor, GraphSAINT: Graph Sampling Based Inductive Learning Method, International Conference on Learning Representations (ICLR), pp. 1–19, 2020
- Zeng, Hanqing, et al. “Deep Graph Neural Networks with Shallow Subgraph Samplers.” arXiv preprint arXiv:2012.01380 (2020).
For our work on GNN acceleration, please see: https://sites.usc.edu/fpga/scalable-graph-analytics-on-emerging-cloud-infrastructure/
Click here for the complete list of publications of all Labs under Prof. Viktor K. Prasanna.