PANDAS/NUMPY:
Pandas: It is an open-source, BSD-licensed library written in Python Language. Pandas provide high performance, fast, easy to use data structures and data analysis tools for manipulating numeric data and time series. Pandas is built on the numpy library and written in languages and can import data from various file formats like JSON, SQL, Microsoft Excel, etc.
# Importing pandas library import pandas as pd # Creating and initializing a nested list age = [['Aman', 95.5, "Male"], ['Sunny', 65.7, "Female"], ['Monty', 85.1, "Male"], ['toni', 75.4, "Male"]] # Creating a pandas dataframe df = pd.DataFrame(age, columns=['Name', 'Marks', 'Gender']) # Printing dataframe df
Numpy: It is the fundamental library of python, used to perform scientific computing. It provides high-performance multidimensional arrays and tools to deal with them. A numpy array is a grid of values (of the same type) that are indexed by a tuple of positive integers, numpy arrays are fast, easy to understand, and give users the right to perform calculations across arrays.
# Importing Numpy package import numpy as np # Creating a 3-D numpy array using np.array() org_array = np.array([[23, 46, 85], [43, 56, 99], [11, 34, 55]]) # Printing the Numpy array print(org_array)
Table of Difference Between Pandas VS NumPy
| PANDAS | NUMPY | |
|---|---|---|
| 1 | When we have to work on Tabular data, we prefer the pandas module. | When we have to work on Numerical data, we prefer the numpy module. |
| 2 | The powerful tools of pandas are Data frame and Series. | Whereas the powerful tool of numpy is Arrays. |
| 3 | Pandas consume more memory. | Numpy is memory efficient. |
| 4 | Pandas has a better performance when number of rows is 500K or more. | Numpy has a better performance when number of rows is 50K or less. |
| 5 | Indexing of the pandas series is very slow as compared to numpy arrays. | Indexing of numpy Arrays is very fast. |
| 6 | Pandas offers 2d table object called DataFrame. | Numpy is capable of providing multi-dimensional arrays. |
PANDAS is really very different then scripting with Python. It’s about using columns and rows, and rarely to never using loops.
Best Resources

https://pandas.pydata.org/Pandas_Cheat_Sheet.pdf
http://datacamp-community-prod.s3.amazonaws.com/da466534-51fe-4c6d-b0cb-154f4782eb54
Series
1-dimensional labeled array – can hold any data type.
s = pd.Series([3, -5, 7, 4], index=['a', 'b', 'c', 'd'])
DataFrame
2-Dim labeled data structure with columns and rows of potentially different types.
df=pd.DataFrame(
[
{'ExpressionDay1':5.3,'ExpressionDay2':2.3},
{'ExpressionDay1':51.3,'ExpressionDay2':2.3},
{'ExpressionDay1':3.3,'ExpressionDay2':0},
{'ExpressionDay1':1.3}
],
index=['KRAS','PTEN','APOE',"MTFMT"])
Importing
import numpy as np import pandas as pd
I/O
In
cancer_county = pd.read_csv("cancer_county.csv")
med_count = pd.read_csv("med_county.csv")
Out
df.to_csv('myDataFrame.csv')
Subsetting
df.iloc[:,[0]] df.iat([0],[0]) df.loc[[0], ['ExpressionDay1']] df.loc[df['ExpressionDay1'] > 5, ['ExpressionDay2']]
Assign
df['ExpressionDay3']= df.ExpressionDay1+df.ExpressionDay2
Grouping
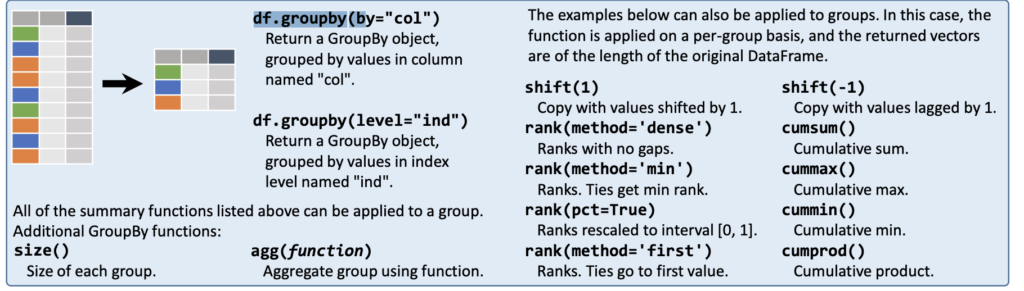
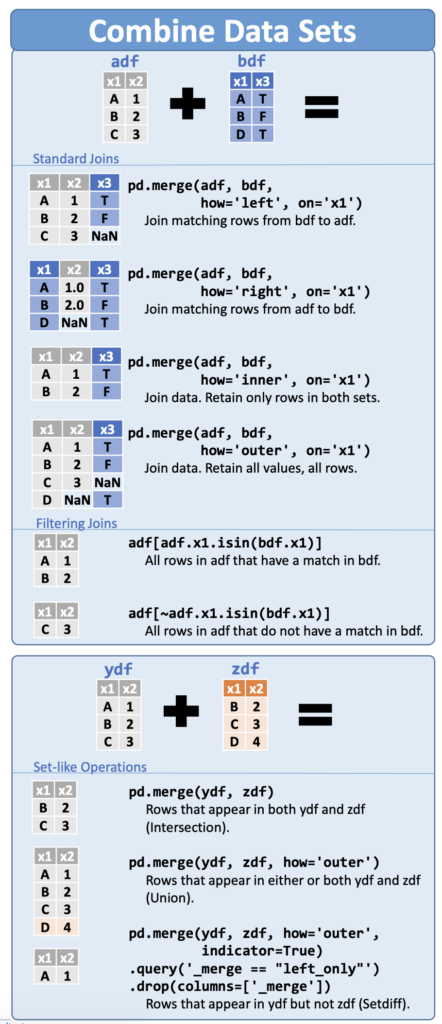
Joins
Functions
len(df) sum() count() # Count non-NA/null values of each object. median() quantile([0.25,0.75]) apply(function) min() max() mean() var() std()